向量数据库深度解析
向量数据库技术的演进历程
向量数据库的发展历程反映了数据处理需求从结构化向非结构化、从精确匹配向语��义理解的深刻转变。这一演进过程可以划分为四个关键阶段。
萌芽与早期探索
向量空间模型的诞生
20世纪60年代提出的向量空间模型(VSM)将文本数据表示为高维向量,通过余弦相似度实现文本检索。这一模型成为早期信息检索系统的理论基石,但受限于当时的计算能力,应用主要停留在学术研究层面。
早期算法的局限性
基于树结构的相似性搜索算法(如k-d树、Ball树)在处理高维数据时遭遇"维度灾难"问题,查询效率随维度增加急剧下降,难以满足实际应用需求。
技术突破与驱动
深度学习的推动
随着深度学习技术的飞速发展,CNN和RNN模型能够将图像、文本等非结构化数据转换为高维稠密向量,催生了海量向量数据的管理需求。
ANN算法成熟
近似最近邻(ANN)算法如LSH、IVF、HNSW等相继成熟,通过牺牲极小精度换取巨大性能提升,为高维向量检索奠定了技术基础。
开源库的出现
2017年,Facebook开源了Faiss库,实现了多种先进ANN算法并针对CPU/GPU深度优化,极大降低了向量检索技术的应用门槛。
独立产品与市场起步
专用向量数据库诞生
2019年,Milvus作为业界首个云原生分布式向量数据库开源,解决了Faiss在企业级应用中的不足。同期Pinecone推出全托管云服务,标志着向量数据库成为独立产品类别。
技术架构分化
技术架构开始分化:以Milvus为代表的分布式架构追求极致性能和扩展性;轻量级产品如Chroma则专注于简洁易用,适合快速原型开发。
AI驱动的爆发与普及
生成式AI与RAG架构
以ChatGPT为代表的生成式AI爆发,RAG(检索增强生成)架构应运而生。向量数据库成为RAG技术栈中不可或缺的环节,是实现LLM与私有数据连接的关键桥梁。
云服务商入局
腾讯云、阿里云等云服务商纷纷推出向量数据库产品,与AI平台深度集成,提供一站式解决方案。LangChain等AI开发框架的兴起进一步简化了向量数据库的应用集成。
关键洞察
向量数据库已经从相对小众的技术领域,发展成为AI时代不可或缺的核心基础设施,其发展轨迹与AI技术的突破紧密相连。
核心技术流派与系统演进
根据拓数派向量数据库负责人邱培峰的观点,当前向量数据库领域主要分化为两大技术流派,随着多模态应用的兴起,也催生了多模态一体化流派。
专有向量数据库
从设计之初就专门为处理向量数据而构建的系统,如Milvus、Pinecone、Qdrant等。
传统数据库扩展
在现有数据库上增加向量功能,如PostgreSQL的pgvector、Elasticsearch等。
多模态一体化
结合多种数据处理能力,如Weaviate,支持文本、图像等多模态数据。
| 维度 | Milvus | Pinecone | Weaviate | Qdrant | Chroma | PGVector | Elasticsearch |
|---|---|---|---|---|---|---|---|
| 技术流派 | 专有/原生 | 专有/原生 | 多模态一体化 | 专有/原生 | 专有/轻量级 | 传统数据库扩展 | 传统数据库扩展 |
| 核心架构 | 分布式,云原生 | 全托管Serverless | 分布式,模块化 | 分布式,云原生 | 单机/轻量集群 | PostgreSQL扩展 | 分布式,多节点 |
| 索引算法 | IVF, HNSW, DiskANN | 自动优化 | HNSW, IVF | HNSW, DiskANN | HNSW | IVFFlat, HNSW | HNSW, IVF |
| 最佳场景 | 企业级集群,十亿级向量 | 快速原型,免运维 | 混合搜索,知识库 | 高性能,云原生 | 本地开发,轻量应用 | 已有PG团队 | 全文+向量混合搜索 |
| 优势 | 高吞吐,GPU加速,高扩展性 | 全托管,免运维,低延迟 | 混合搜索强,内置模型 | Rust实现,高性能 | 零依赖,简单易用 | 无需新系统,SQL原生 | 成熟生态,功能全面 |
| 局限 | 运维成本高,部署复杂 | 成本较高,供应商锁定 | 部署复杂,资源需求高 | 生态较小 | 不适合大规模 | 索引能力较弱 | 向量搜索非核心 |
Milvus: 开源分布式系统
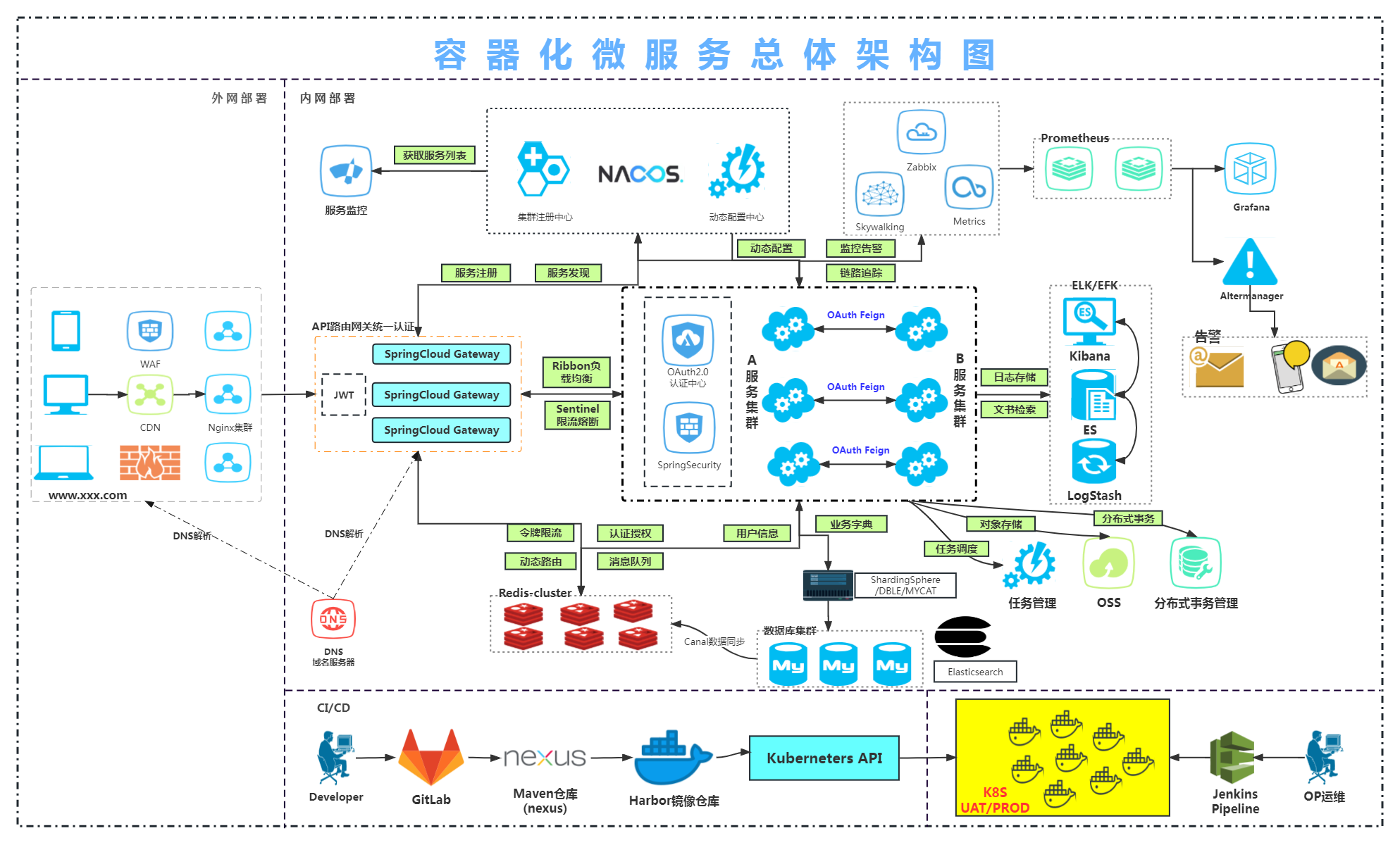
Milvus采用云原生架构,所有组件均为无状态服务,计算与存储分离,支持Kubernetes部署。支持多种ANN算法和GPU加速,适合处理海量数据。
深度技术分析:数据模型与索引技术
基于不同数据模型的比较
键值模型
以Redis为代表,向量作为值与键关联存储。利用高效内存操作提供极低延迟,适合简单查询场景。
基于不同索引技术的比较
其他重要索引技术
核心应用场景与价值
检索增强生成 (RAG)
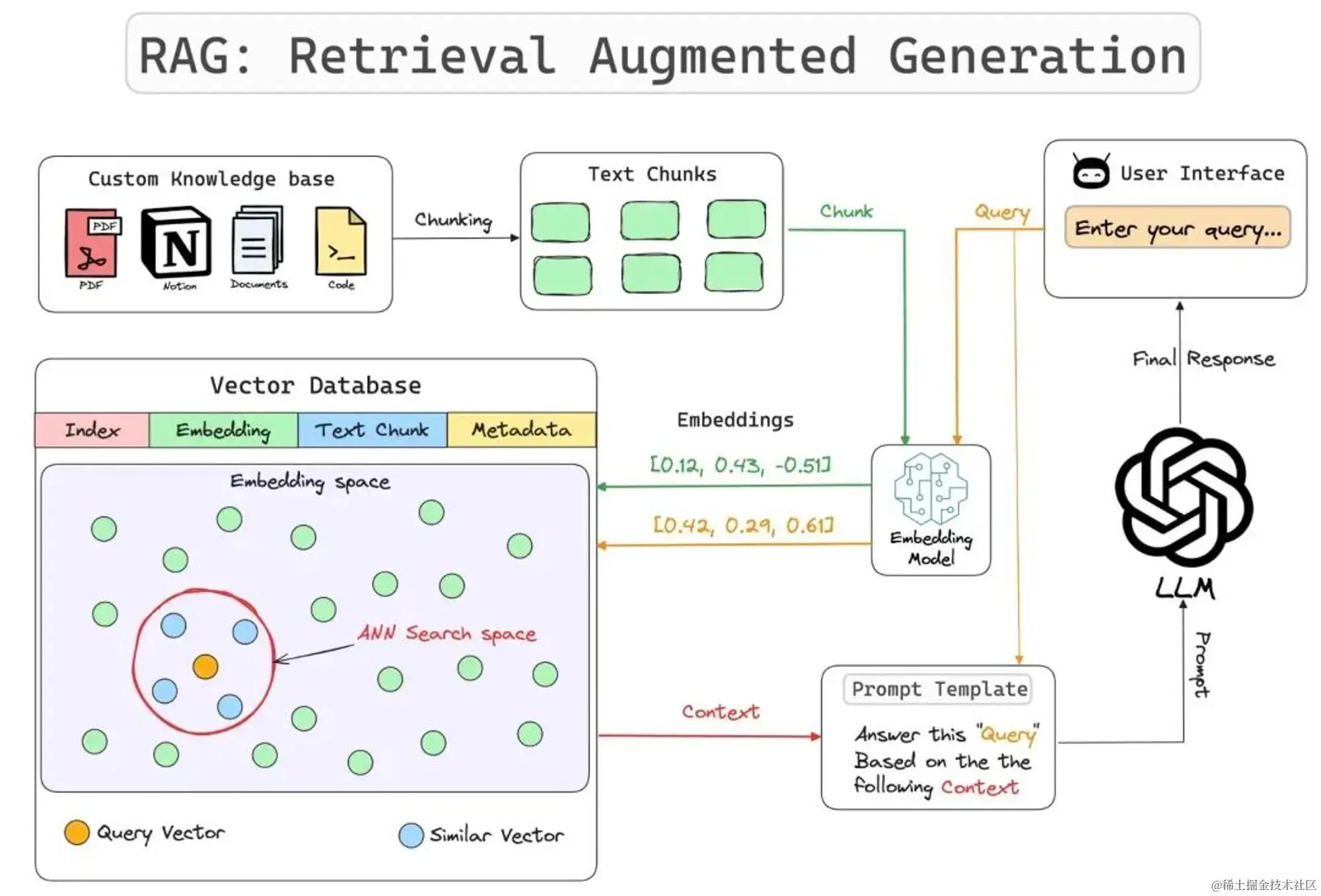
向量数据库是RAG架构的"记忆中枢"。在生成答案前,先从知识库检索相关信息作为上下文,有效解决LLM的"幻觉"问题。
关键价值
向量数据库的检索质量和效率直接决定RAG系统最终答案的准确性和响应速度,是整个流程的关键瓶颈点。
语义搜索与推荐
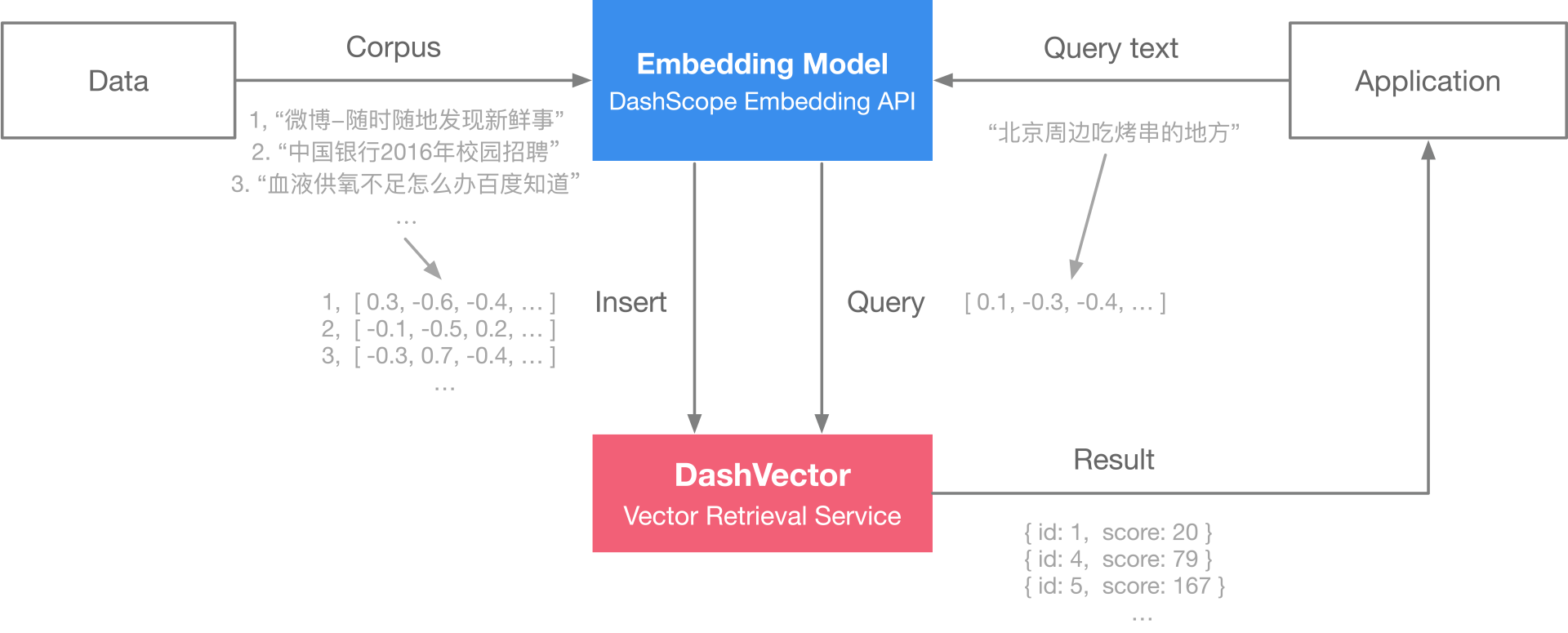
实现真正的语义搜索,理解词语背后的深层含义,即使查询和文档没有完全匹配的关键词也能找到相关内容。
应用场景
在推荐系统中计算用户向量与物品向量的相似度,发现更深层次的非显性关联,提供精准个性化推荐。
多媒体内容检索
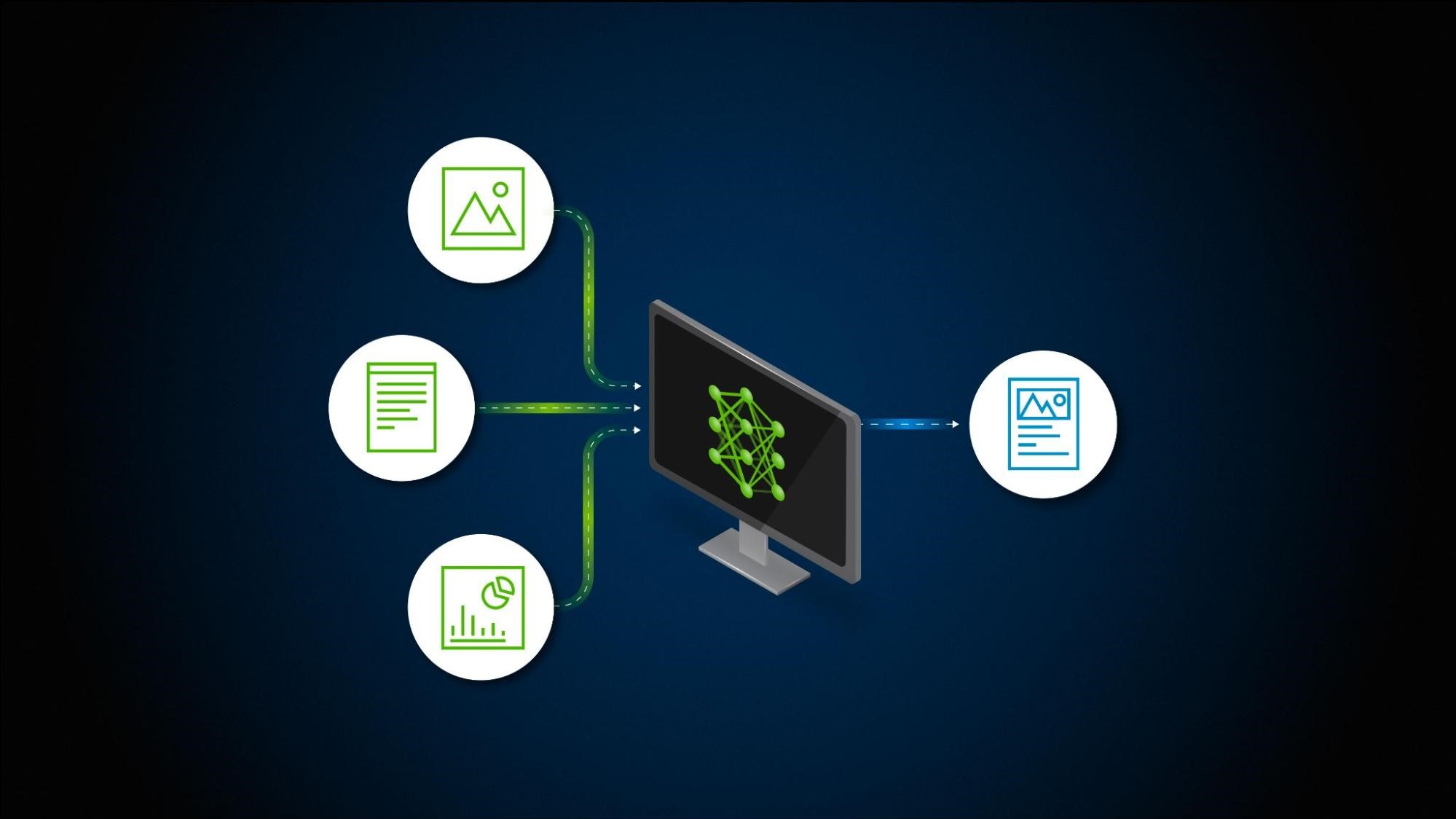
将图像、视频、音频转换为语义向量,实现以图搜图、以视频搜视频、以音搜音等功能,极大提升多媒体内容利用效率。
用户画像与个性化

将用户行为数据融合成高维向量,动态反映用户实时兴趣和长期偏好,实现"千人千面"的个性化服务。
未来发展趋势与展望
多模态数据融合
未来AI应用需要处理和融合文本、图像、音频、视频等多模态数据。向量数据库将支持在统一向量空间中进行联合表示和跨模态检索。
发展趋势:用户将能够上传图片并输入文字描述,系统返回同时满足图像和文本语义的��综合结果。
云原生与Serverless化
云原生架构和Serverless化将成为标配,实现资源按需分配和自动伸缩,极大降低使用门槛和运维成本。
发展趋势:更多产品将提供类似Pinecone的无服务器体验,按实际使用量付费。
与AI生态深度融合
向量数据库将与机器学习框架、大模型应用开发框架、嵌入模型提供商等无缝集成,形成完整闭环。
发展趋势:简化AI应用开发流程,从数据处理到语义检索的一站式解决方案。
性能与成本平衡
通过先进索引算法、向量压缩技术、智能查询优化等手段,在性能和成本之间找到最佳平衡点。
发展趋势:DiskANN、PQ等技术将更广泛应用,提供灵活的部署选项满足不同需求。
未来架构愿景
统一存储
多模态数据统一向量表示
智能检索
跨模态语义理解与匹配
弹性扩展
云原生架构按需伸缩
结语
向量数据库作为AI时代的关键基础设施,正在从专业技术领域走向广泛应用。随着多模态融合、云原生化、生态集成等技术趋势的发展,向量数据库将在未来AI应用中发挥更加重要的作用,成为连接数据与智能的重要桥梁。